📒 Today I Learn/🤖 Machine Learning
[머신러닝 심화] 분류와 회귀 모델링 심화 실습
se0ehe
2024. 8. 13. 17:12

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import DecisionTreeClassifier, plot_tree
titanic_df = pd.read_csv('C:/Users/82109/OneDrive/문서/ML/titanic/train.csv')타이타닉 데이터를 이용하여 의사결정 나무를 그려보자!
✳️ 의사결정 나무(Decision Tree) 실습
- 먼저 이용할 변수들에 대해 처리해줘야할 전처리 실시
X_features = ['Pclass', 'Sex', 'Age']
# Pclass : 라벨인코딩
# Sex : 라벨인코딩
# Age : 결측치를 평균으로 대치, 스케일링은 따로 하지 않겠음
le = LabelEncoder()
titanic_df['Sex'] = le.fit_transform(titanic_df['Sex'])
le2 = LabelEncoder()
titanic_df['Pclass'] = le2.fit_transform(titanic_df['Pclass'])
age_mean = titanic_df['Age'].mean()
titanic_df['Age'] = titanic_df['Age'].fillna(age_mean)
- 모델 적용과 의사결정나무 시각화
# 변수 지정
X = titanic_df[X_features]
y = titanic_df['Survived']
# 모델 적용
# max_depth에 따라 나무의 성장을 제한 할 수 있다.
model_dt = DecisionTreeClassifier(max_depth=1)
model_dt.fit(X,y)
# 그림그리기
plt.figure(figsize = (10, 5))
# sklearn.tree에 나무 그림을 그릴 수 있는 것이 있다(plot_tree)
plot_tree(model_dt, feature_names=X_features, class_names=['Not Survived', 'Survived'], filled =True)
plt.show()
- 성별을 기준으로 나누어 분류를 해본 것이다.
- filled를 통해 노드에 색칠을 할 수 있는데 양성(생존)은 파랑색, 음성(사망)은 주황색이고 색의 진함은 각 class에 비율에 따라 높을수록 진해진다.
- feature_names는 모델링할 때 이용한 데이터셋의 feature 이름을 리스트로 입력
- class_name은 모델링할 때 이용한 데이터셋의 target 이름을 리스트로 입력
✳️ 랜덤포레스트(RandomForest) 실습
지금까지 배웠던 것들을 같이 비교 해보자! (같은 데이터 이용)
# 로지스틱회귀, 의사결정나무, 랜덤포레스트
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
# 평가 도구 가져오기
from sklearn.metrics import accuracy_score, f1_score
# 모델 가져오기
model_lor = LogisticRegression()
model_dt = DecisionTreeClassifier(random_state=42)
model_rf = RandomForestClassifier(random_state=42)
# 훈련
model_lor.fit(X, y)
model_dt.fit(X, y)
model_rf.fit(X, y)
# 예측
y_lor_pred = model_lor.predict(X)
y_dt_pred = model_dt.predict(X)
y_rf_pred = model_rf.predict(X)
# 평가를 위한 함수 생성
def get_score(model_name, y_true, y_pred):
acc = accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(model_name, '정확도 : ', acc, 'f1-score : ', f1)
get_score('lor', y, y_lor_pred)
get_score('dt', y, y_dt_pred)
get_score('rf', y, y_rf_pred)
- 선형회귀와 의사결정나무, 랜덤포레스트를 적용했을 때 정확도와 f1-score를 알아보았다.
- 선형회귀보다는 의사결정나무나 랜덤포레스트를 적용한 것이 더 성능이 좋은 것처럼 보인다.
- X_features에 대한 중요도 표시를 통해 어떤 변수가 중요한지 알아보기
X_features
model_rf.feature_importances_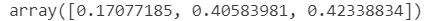
나온 값에 의하면, Age의 값이 가장 큰 걸 보니 '나이 변수'가 제일 중요하다는 것을 알 수 있다.
✳️ 전체 실습
이제 KNN과 부스팅까지 같이 적용해서 실습을 해보기로 하자!
- 먼저 부스팅을 위한 패키지를 설치한다.
# 설치
! pip install xgboost
! pip install lightgbm
- KNN과 부스팅 모델들 적용 및 평가
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
# 모델 가져오기
model_knn = KNeighborsClassifier()
model_gbm = GradientBoostingClassifier(random_state=42)
model_xgb = XGBClassifier(random_state=42)
model_lgb = LGBMClassifier(random_state=42)
# 훈련
model_knn.fit(X, y)
model_gbm.fit(X, y)
model_xgb.fit(X, y)
model_lgb.fit(X, y)
# 예측
y_knn_pred = model_knn.predict(X)
y_gbm_pred = model_gbm.predict(X)
y_xgb_pred = model_xgb.predict(X)
y_lgb_pred = model_lgb.predict(X)
# 평가 (모두 비교해보기)
get_score('lor', y, y_lor_pred)
get_score('dt', y, y_dt_pred)
get_score('rf', y, y_rf_pred)
get_score('knn', y, y_knn_pred) # 좋은 결과가 안나올 것이다! 스케일링을 안했기 때문!
get_score('gbm', y, y_gbm_pred)
get_score('xgb', y, y_xgb_pred)
get_score('lgb', y, y_lgb_pred)
- knn은 예상대로 높지 않은 평가도를 보여줬다.
- gbm, xgb, lgb(부스팅)도 랜덤포레스트와 비교했을 때 엄청 높진 않았다. (타이타닉 데이터는 적기 때문에 과적합이 있을 수 있음)
🪄 성능 개선을 위해 다양한 변수를 추가하여 실습
좀 더 모델의 성능을 높여보기 위해서 x변수에 다른 변수들을 추가해보고 실습해보았다.
- 추가된 변수는 따로 전처리가 필요가 없었던 'Fare'와 비교적 전처리가 간단했던 'Embarked'를 이용하였다.
X2_features = ['Pclass', 'Sex', 'Age', 'Fare', 'Embarked']
# Pclass : 라벨인코딩
# Sex : 라벨인코딩
# Age : 결측치를 평균으로 대치, 스케일링은 따로 하지 않겠음
# Fare : 따로 스케일링 하지 않겠음
# Embarked : 최빈값 = 'S'로 대치, 라벨인코딩
le = LabelEncoder()
titanic_df['Sex'] = le.fit_transform(titanic_df['Sex'])
le2 = LabelEncoder()
titanic_df['Pclass'] = le2.fit_transform(titanic_df['Pclass'])
age_mean = titanic_df['Age'].mean()
titanic_df['Age'] = titanic_df['Age'].fillna(age_mean)
titanic_df['Embarked'] = titanic_df['Embarked'].fillna('S')
le3 = LabelEncoder()
titanic_df['Embarked'] = le3.fit_transform(titanic_df['Embarked'])
# 변수 지정
X2 = titanic_df[X2_features]
y = titanic_df['Survived']
- 모델 훈련 및 평가
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
# 모델 가져오기
model_lor = LogisticRegression()
model_dt = DecisionTreeClassifier(random_state=42)
model_rf = RandomForestClassifier(random_state=42)
model_knn = KNeighborsClassifier()
model_gbm = GradientBoostingClassifier(random_state=42)
model_xgb = XGBClassifier(random_state=42)
model_lgb = LGBMClassifier(random_state=42)
# 훈련
model_lor.fit(X2, y)
model_dt.fit(X2, y)
model_rf.fit(X2, y)
model_knn.fit(X2, y)
model_gbm.fit(X2, y)
model_xgb.fit(X2, y)
model_lgb.fit(X2, y)
# 예측
y_lor_pred = model_lor.predict(X2)
y_dt_pred = model_dt.predict(X2)
y_rf_pred = model_rf.predict(X2)
y_knn_pred = model_knn.predict(X2)
y_gbm_pred = model_gbm.predict(X2)
y_xgb_pred = model_xgb.predict(X2)
y_lgb_pred = model_lgb.predict(X2)
# 평가 (모두 비교해보기)
get_score('lor', y, y_lor_pred)
get_score('dt', y, y_dt_pred)
get_score('rf', y, y_rf_pred)
get_score('knn', y, y_knn_pred) # 좋은 결과가 안나올 것이다! 스케일링을 안했기 때문!
get_score('gbm', y, y_gbm_pred)
get_score('xgb', y, y_xgb_pred)
get_score('lgb', y, y_lgb_pred)
- 좀 더 정확도와 f1-score를 높일 수 있었다. (의사결정나무, 랜덤포레스트, 부스팅 알고리즘들)