

타이타닉 데이터를 이용하고,
살아남은 승객을 예측하는 모델을 만들어서 train과 test를 구분 지어두고 train 데이터로 모델을 학습 시킨 뒤,
test 데이터에 적용하여 결과를 토대로 얼마나 예측을 잘 해냈는지 캐글에서 확인해보기!
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns먼저 필요한 라이브러리들을 불러온다.
✳️ 데이터 로드 & 분리
- train / test 데이터 분리
train_df = pd.read_csv('C:/Users/82109/OneDrive/문서/ML/titanic/train.csv')
test_df = pd.read_csv('C:/Users/82109/OneDrive/문서/ML/titanic/test.csv')
☑️ 카피본 데이터 생성
- 원래 데이터를 해치지 않기 위해 데이터를 카피하여 변수에 할당한다.
train_df_2 = train_df.copy()
✳️ 탐색적 데이터 분석(EDA)
- 분포 확인 및 이상치 확인
☑️ info를 통해 정보 확인
train_df.info()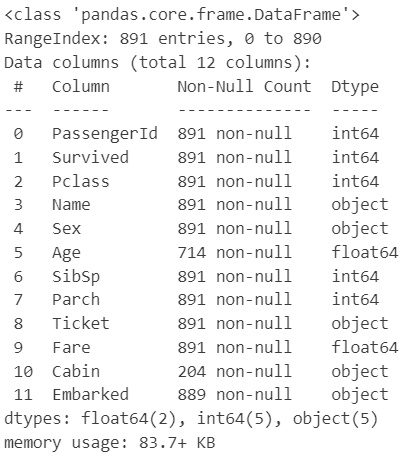
Age, Cabin, Fare에 결측치가 있다.
☑️ describe를 통해 기초 통계 확인
train_df.describe(include='all')
- Age의 평균은 약 29.7
- SibSp와 Parch는 가족관계에 대한 정보
- Fare에 최대값이 512달러로 너무 큰 금액을 가지고 있다.
- Fare의 평균은 약 32.2
- Embarked의 최빈값은 'S'
✳️ 데이터 전처리
나중에 test 데이터에도 적용하기 위해 함수를 생성하여 적용할 수 있도록 할 것이다.
1️⃣ 결측치 처리
- 수치형 : Age
- 범주형 : Embarked
- 삭제 : Cabin, Name
☑️ Age의 이상치 처리
train_df_2 = train_df_2[train_df_2['Fare'] < 512]
☑️ 결측치 처리를 위한 함수 생성
# 수치형 : 평균으로 대치
# 범주형 : 최빈값으로 대치 -> 'S'
def get_non_missing(df):
# Age 평균으로 대치
Age_mean = train_df_2['Age'].mean()
df['Age'] = df['Age'].fillna(Age_mean)
# train 데이터에는 필요하지 않지만 test 데이터의 Fare 결측치가 있어서 평균으로 대치
Fare_mean = train_df_2['Fare'].mean()
df['Fare'] = df['Fare'].fillna(Fare_mean)
# Embarked 결측치 최빈값으로 대치
df['Embarked'] = df['Embarked'].fillna('S')
return dfget_non_missing(train_df_2).info()
- Cabin을 제외한 결측치가 잘 처리 되어졌다.
☑️ 데이터 삭제
- 데이터를 불러오지 않는다면 따로 삭제할 필요가 없기 때문에 처리를 따로 하진 않았다.
2️⃣ 데이터 전처리
- 수치형 : Age, Fare, SibSp+Parch
- 범주형
- 레이블 인코딩 : Pclass, Sex
- 원 - 핫 인코딩 : Embarked
☑️ Family 변수 생성 (SibSp+Parch)
def get_family(df):
df['Family'] = df['SibSp'] + df['Parch'] + 1 # 혼자 있는 가구면 1, 여러 명이면 2
return dfget_family(train_df_2).head(3)
☑️ pairplot을 통한 숫자형 변수들의 분포 및 이상치 확인
sns.pairplot(train_df_2[['Age', 'Fare', 'Family']])
☑️ 수치형 데이터 전처리
def get_numeric_sc(df):
# sd_sc : Fare, mm_sc : Age, Family
from sklearn.preprocessing import StandardScaler, MinMaxScaler
sd_sc = StandardScaler()
mm_sc = MinMaxScaler()
# sd_sc
# 학습은 train 데이터
sd_sc.fit(train_df_2[['Fare']])
# 학습된 것을 적용해서 넣을 곳은 원래 데이터
df['Fare_sd_sc'] = sd_sc.transform(df[['Fare']])
# mm_sc
# 학습은 train 데이터
mm_sc.fit(train_df_2[['Age', 'Family']])
# 학습된 것을 적용해서 넣을 곳은 원래 데이터
df[['Age_mm_sc', 'Family_mm_sc']] = mm_sc.transform(df[['Age', 'Family']])
return dfget_numeric_sc(train_df_2).describe()
초기 데이터와 비교를 해보면 함수를 통해 각각 Fare_sd_sc와 Age_mm_sc, Family_mm_sc가 잘 추가 된 것을 확인할 수 있다.
☑️ 범주형 데이터 전처리
def get_category(df):
# le : Pclass, Sex, oe : Embarked
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
le = LabelEncoder()
le2 = LabelEncoder()
oe = OneHotEncoder()
# le
le.fit(train_df_2[['Pclass']])
df['Pclass_le'] = le.transform(df['Pclass'])
# le2
le2.fit(train_df_2[['Sex']])
df['Sex_le'] = le2.transform(df['Sex'])
# index reset을 위한 구문 -> Fare 요금 중 512달러인 걸 제거 했었는데 이때 인덱스 리셋이 안되어서
df = df.reset_index()
# oe
oe.fit(train_df_2[['Embarked']])
embarked_csr = oe.transform(df[['Embarked']])
# 원핫인코딩은 한 차례 더 과정이 필요
# 학습된 내용을 가지고 인코딩한 자료는 너무 크기 때문에 데이터 프레임화 하면서 어레이 형식으로 바꿔줘야 한다.
# get_feature_names_out은 Embarked_S 이런 식으로 컬럼명을 지정해줄 수 있다.
embarked_csr_df = pd.DataFrame(embarked_csr.toarray(), columns = oe.get_feature_names_out())
# 만들어진 csr_df를 기존 df와 붙이기 위해 concat을 해준다.
df = pd.concat([df, embarked_csr_df], axis = 1)
return dftrain_df_2 = get_category(train_df_2)
train_df_2.head(3)
Pclass_le, Sex_le, Embarked_C, Embarked_Q, Embarked_S가 모두 잘 적용되어 데이터프레임 형태로 잘 저장되어졌다.
✳️ 모델 수립
def get_model(df):
from sklearn.linear_model import LogisticRegression
model_lor = LogisticRegression()
X = df[['Age_mm_sc', 'Fare_sd_sc', 'Family_mm_sc', 'Pclass_le', 'Sex_le', 'Embarked_C', 'Embarked_Q', 'Embarked_S']]
y = df[['Survived']]
return model_lor.fit(X, y)model_output = get_model(train_df_2)
model_output
☑️ 예측
X = train_df_2[['Age_mm_sc', 'Fare_sd_sc', 'Family_mm_sc', 'Pclass_le', 'Sex_le', 'Embarked_C', 'Embarked_Q', 'Embarked_S']]
y_pred = model_output.predict(X)
✳️ 모델 평가
from sklearn.metrics import accuracy_score, f1_score
print(accuracy_score(train_df_2['Survived'], y_pred))
print(f1_score(train_df_2['Survived'], y_pred))
💟 test 데이터에 적용하기
test_df.head()
☑️ info를 통해 정보 확인
test_df.info()
☑️ test 데이터에도 함수 적용하기
test_df_2 = get_family(test_df)test_df_2 = get_non_missing(test_df)test_df_2 = get_numeric_sc(test_df)test_df_2 = get_category(test_df)
test_df_2.info()
초기 데이터와 달리 함수가 잘 적용되어 컬럼들이 모두 추가 되고 결측치 부분도 쓰지 않을 Cabin을 제외하고는 모두 잘 처리된 것으로 보여진다.
☑️ test 데이터 만들어진 모델을 이용하여 예측
test_X = test_df_2[['Age_mm_sc', 'Fare_sd_sc', 'Family_mm_sc', 'Pclass_le', 'Sex_le', 'Embarked_C', 'Embarked_Q', 'Embarked_S']]
y_test_pred = model_output.predict(test_X)
이제 해당 결과를 데이터로 저장해서 캐글에 업로드해 정답 모델과 얼마나 잘 일치하는지 확인해보자!
☑️ 캐클에서 준 Gender을 이용한 생존 여부 확인 데이터 틀에 맞추기
캐글에서 원하는 데이터 형태가 있기 때문에 가장 쉽게 맞추기 위해 제공해준 데이터의 Survived 값을 변경해 줄 것이다.
sub_df = pd.read_csv('C:/Users/82109/OneDrive/문서/ML/titanic/gender_submission.csv')
sub_df.head()
☑️ test 데이터로 예측한 Survived 값으로 변경
sub_df['Survived'] = y_test_pred
sub_df
☑️ 데이터 저장
sub_df.to_csv('./result.csv', index = False)
잘 저장되어 캐글에 업로드를 해보러 가자!

0.77033의 점수를 받으며 나름 높은 점수를 받았다. 고인물들은 1점을 딱 맞춰낸 분들도 있지만.. 이렇게 실습을 하며 머신러닝을 다뤄본 것에 의의를 두며 실습을 마친다...!
'📒 Today I Learn > 🤖 Machine Learning' 카테고리의 다른 글
| [머신러닝 심화] 분류와 회귀 모델링 심화 실습 (0) | 2024.08.13 |
|---|---|
| [머신러닝 심화] 분류와 회귀 모델링 심화 이론 (0) | 2024.08.13 |
| [머신러닝 기초] 로지스틱회귀 실습 (0) | 2024.08.12 |
| [머신러닝 기초] 로지스틱회귀(분류 분석) 이론 (0) | 2024.08.12 |
| [머신러닝 기초] 선형회귀 정리 (0) | 2024.08.09 |