
2024.07.15
오늘도 판다스를 이용한 빅분기 문제풀이를 하며 다양한 method와 모듈 이용을 공부하였당

🔒 31번) df의 new_price 컬럼 값에 따라 내림차순으로 정리하고 index를 초기화 해라
내림차순 저번에 했던거 써먹기~
🔓 해결 방법
df.sort_values('new_price', ascending=False).reset_index(drop=True)
ascending=True 가 디폴트 값이라 오름차순은 굳이 입력을 해주지 않아도 되지만, 내림차순은 False로 표시를 해줘야 한다.
🔒 32번) df의 item_name 컬럼 값이 Steak Salad 또는 Bowl 인 데이터를 인덱싱하라
Steak Salad or Bowl인 데이터 출력하기
🔓 해결 방법
df.loc[(df['item_name'] == 'Steak Salad') | (df['item_name'] == 'Bowl')]
다중조건으로 또는의 조건을 맞춰 | 를 이용해준다.
🔒 33번) df의 item_name 컬럼 값이 Steak Salad 또는 Bowl 인 데이터를 데이터 프레임화 한 후, item_name을 기준으로 중복행이 있으면 제거하되 첫번째 케이스만 남겨라
위 조건 충족, 중복행 제거 후 첫 번째 케이스만 남기기
🔓 해결 방법
df.loc[(df['item_name'] == 'Steak Salad') | (df['item_name'] == 'Bowl')].drop_duplicates('item_name')
.drop_duplicates 을 이용하여 중복행을 제거해준다. 이 메소드의 기본값은 첫번째 케이스만 남기는 것이다.
(여기서 Bowl이 여러 개 있으면 그 중 가장 첫 번째 행을 출력하고 Steak Salad도 마찬가지로 가장 첫 번째 행을 출력한 것이다.)
🔒 34번) df의 item_name 컬럼 값이 Steak Salad 또는 Bowl 인 데이터를 데이터 프레화 한 후, item_name를 기준으로 중복행이 있으면 제거하되 마지막 케이스만 남겨라
같은 메소드를 이용해서 라스트 케이스만 남기
🔓 해결 방법
df.loc[(df['item_name'] == 'Steak Salad') | (df['item_name'] == 'Bowl')].drop_duplicates('item_name', keep='last')
마지막 케이스만 남기기 위해 keep='last'라는 조건을 넣어줬다.
▼ drop_duplicates 관련 내용
https://se0ehe.tistory.com/107
[Pandas] .drop_duplicates( ) : 데이터프레임 중복 제거
2024.07.15 ✳️ .drop_duplicates( )데이터프레임에서 중복되는 행을 제거하고 고유한 값만 남기고 싶을 때 쓰는 methodimport pandas as pddf.drop_duplicates() 🔹 중복제거df.drop_duplicates()아무것도 지정하지 않
se0ehe.tistory.com
🔒 35번) df의 데이터 중 new_price값이 new_price값의 평균값 이상을 가지는 데이터들을 인덱싱하라
평균값과 기존값을 이용한 비교 및 출력하기
🔓 해결 방법
df.loc[df['new_price'] >= df['new_price'].mean()]
.mean( ) 을 사용하여 해당 컬럼의 평균을 구할 수 있었고, 조건으로 평균값 이상 '>='을 써주며 비교하여 출력하였다.
🔒 36번) df의 데이터 중 item_name의 값이 Izze 데이터를 Fizzy Lizzy로 수정하라
Izze를 Fizzy Lizzy로 변경하기
🔓 해결 방법
df.loc[df['item_name'] == 'Izze', 'item_name'] = 'Fizzy Lizzy'어떤 특정 컬럼에 대해 값을 바꾸는 경우에는 꼭 loc를 써줘야 한다.
이 코드를 통해서 Izze가 Fizzy Lizzy로 변경을 시킨 것인데 잘 되었는지 확인해보자.
df.loc[df['item_name'] == 'Izze']
기존의 값을 입력해보니 아무것도 뜨지 않는다.
df.loc[df['item_name'] == 'Fizzy Lizzy']
바뀐 값으로 코드를 입력하니 제대로 값이 변경된 상태로 출력이 되는 것을 확인할 수 있다.
▼ 값 바꾸기 관련 내용
https://se0ehe.tistory.com/108
[Pandas] 데이터프레임 값 바꾸기 (변경, replace)
2024.07.15 ✳️ 값 바꾸기🔹값 1개만 변경df.loc[행의 인덱스, '컬럼명'] = 바꿀 값 🔹특정 열 통째로 변경# 한가지 값으로 변경할 경우df.loc['컬럼명'] = 바꿀 값# 리스트 내역으로 변경할 경우df.loc
se0ehe.tistory.com
🔒 37번) df의 데이터 중 choice_description 값이 NaN 인 데이터의 수를 구하여라
null 값인 결측치의 개수 구하기
🔓 해결 방법
df['choice_description'].isnull().sum()
# 1246.isnull( )을 이용하여 결측치를 확인하고 .sum( )을 이용하여 트루인 것의 합을 구하였다.
🔒 38번) df의 데이터 중 choice_description 값이 NaN 인 데이터를 NoData 값으로 대체하라(loc 이용)
결측치를 'NoData'로 변경하기
🔓 해결 방법
1. .loc[ ]와 .isnull( )을 이용하기
df.loc[df['choice_description'].isnull(),'choice_description'] ='NoData'loc[ ]를 이용하여 조건 부분에 .isnull() 인 것을 써주며 바꿀 값을 제시하는 방법이 있다.
2. .fillna( ) : 결측치를 채우는 method이다.
df.loc[:, 'choice_description'] = df['choice_description'].fillna('NoData').loc를 똑같이 이용하면서 조건과 바꿀 행을 제시하고 바꿀 값에 fillna() 메소드를 이용하여 채워줄 값을 제시할 수 있다.
변경이 잘 되었는지 확인을 해보면,
df.loc[df['choice_description'] == 'NoData']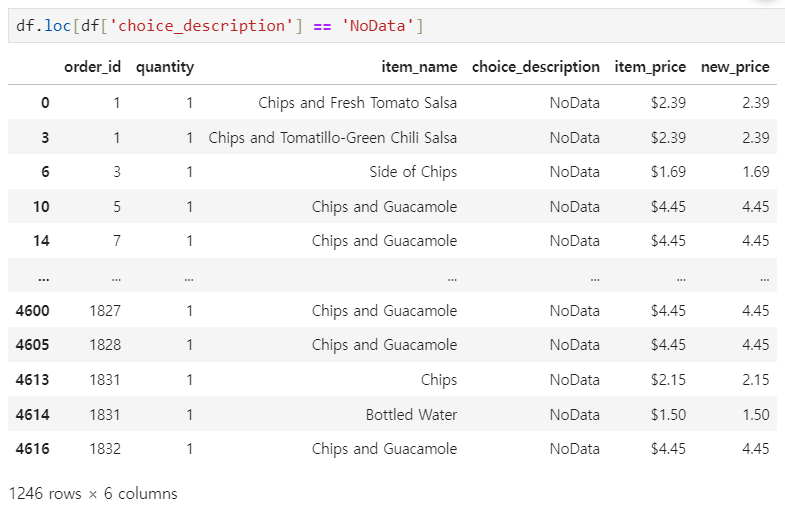
값이 잘 변경된 것을 확인할 수 있었고
df.loc[df['choice_description'].isnull()]
결측치도 잘 사라진 걸 확인할 수 있다.
🔒 39번) df의 데이터 중 choice_description 값에 Black이 들어가는 경우를 인덱싱하라
Black이 들어간 값 찾기
🔓 해결 방법
df.loc[df['choice_description']str.contains('Black')]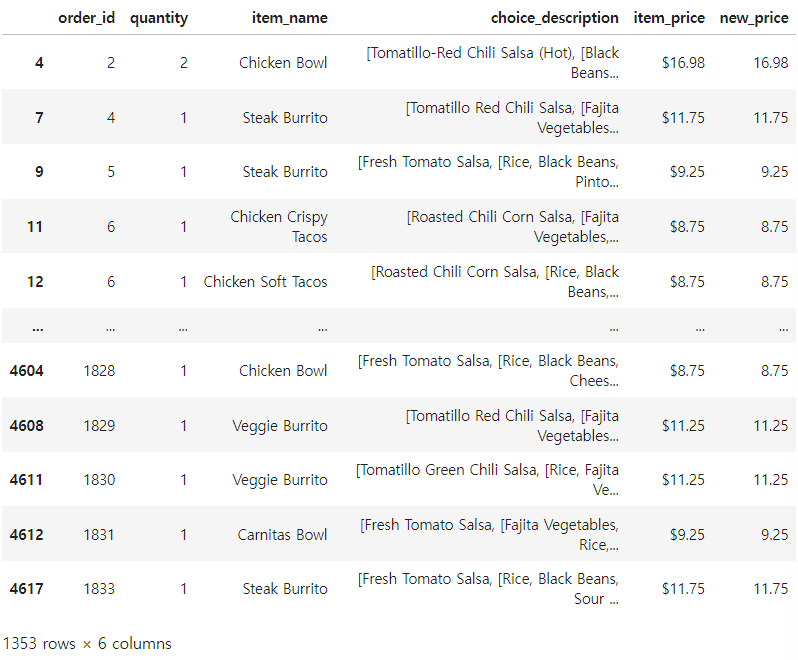
.contains( ) 를 이용하여 'Black'이 들어간 값을 출력하였다.
▼ contains 관련 내용
https://se0ehe.tistory.com/109
[Python] 파이썬에서 like 검색 - .str.startswith() & .str.contains()
2024.07.15 문제를 풀다보니 %어쩌고저쩌고% 포함된 글자면 출력해줘~ 라고 하는 걸 보면 sql의 like를 그렇게 그리워 했는데 파이썬에도 비슷한 기능이 있어 정리한다. 먼저 예시로 다음과 같은
se0ehe.tistory.com
df['choice_description']str.contains('Black')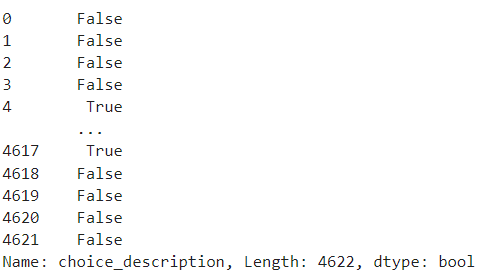
boolean을 통해서 보면 어떤 것이 'Black'이 들어가 있고 없고를 True 와 False를 통해 알 수 있었다.
🔒 40번) df의 데이터 중 choice_description 값에 Vegetables 들어가지 않는 경우의 개수를 출력하라
Vegetables가 없는 경우의 개수를 출력하기
🔓 해결 방법
# Vegetables 가 포함된 경우의 개수
df.loc[df['choice_description'].str.contains('Vegetables')].shape[0]
# 722먼저 'vegetables' 가 포함된 행을 세어보면 722가 나왔다.
이제 포함하지 않는 것을 도출해내야 한다.
df['choice_description']str.contains('Vegetables')
먼저 boolean 타입으로 'vegetables' 가 포함되어 있는지를 참 거짓으로 알아보았다.
~df['choice_description']str.contains('Vegetables')
여기서 '~' 표시를 앞쪽에 해주게 되면 참과 거짓이 뒤바뀌게 된다.
# Vegetables가 없는 경우의 개수
df.loc[~df['choice_description']str.contains('Vegetables')].shape[0]
# 3900그래서 false인 값의 행을 카운팅하면 3900개라는 결과를 얻어낼 수 있다.
len(df.loc[~df['choice_description']str.contains('Vegetables')])
# 3900len( )을 써서도 알 수 있다.
🔒 41번) df의 데이터 중 item_name 값이 N으로 시작하는 데이터를 모두 추출하라
'N'으로 시작하는 데이터 출력하기
🔓 해결 방법
df['item_name'].str
# <pandas.core.strings.accessor.StringMethods at 0x20e00e4d520>df['item_name'].str[0] == 'N'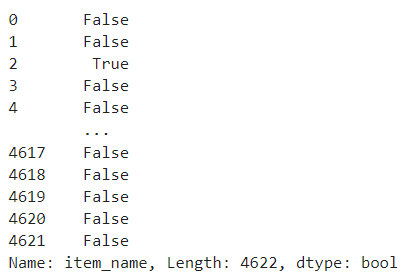
df.loc[df['item_name'].str[0] == 'N']
df[df.item_name.str.startswith('N')]
▼startswith 관련 내용
https://se0ehe.tistory.com/109
[Python] 파이썬에서 like 검색 - .str.startswith() & .str.contains()
2024.07.15 문제를 풀다보니 %어쩌고저쩌고% 포함된 글자면 출력해줘~ 라고 하는 걸 보면 sql의 like를 그렇게 그리워 했는데 파이썬에도 비슷한 기능이 있어 정리한다. 먼저 예시로 다음과 같은
se0ehe.tistory.com
🔒 42번) df의 데이터 중 item_name 값의 단어 개수가 15개 이상인 데이터를 인덱싱하라
단어의 개수가 15개 이상인 것을 출력
🔓 해결 방법
df.loc[df['item_name'].str.len() >= 15]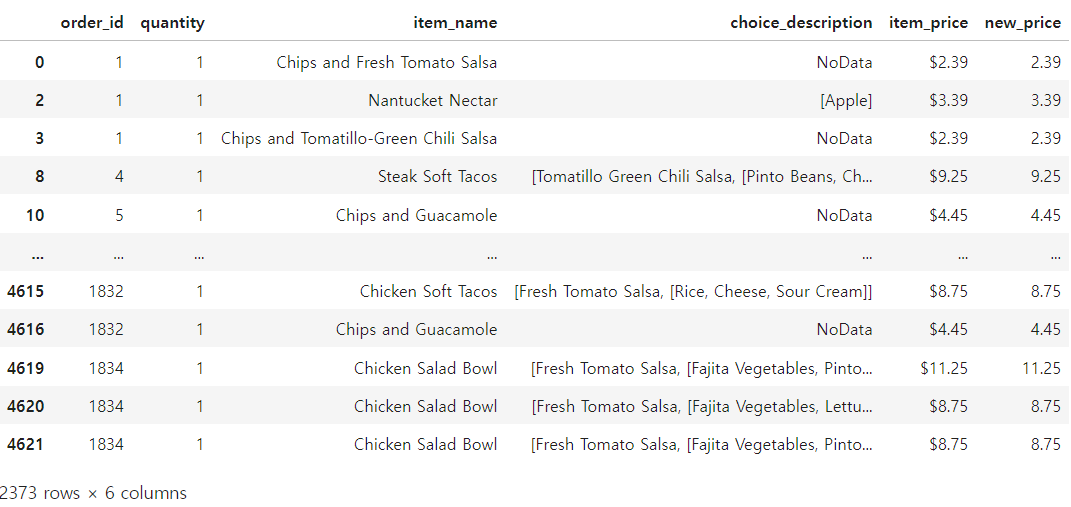
해당 컬럼에 그대로 len()을 쓰게 되면 값의 글자 하나하나를 세어주는 것이 아니라
그래서 .str.len()을 해주면서 값의 하나하나를 카운팅할 수 있게 만들어줬다.
df['item_name'].str.len()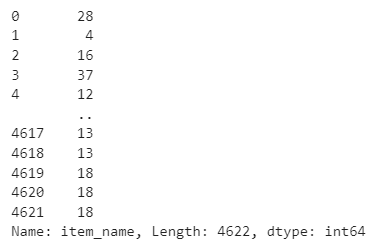
시리즈 타입으로 보면 이렇게 각 글자의 개수를 파악할 수 있는데
df['item_name'].str.len() >= 15
이렇게 boolean 타입으로 보면 참 거짓으로 표현 되고 이것을 데이터프레임으로 뽑아내어 확인한 결과가 위와 같은 결과이다.
🔒 43번) df의 데이터 중 new_price값이 lst에 해당하는 경우의 데이터 프레임을 구하고 그 갯수를 출력하라
list =[1.69, 2.39, 3.39, 4.45, 9.25, 10.98, 11.75, 16.98]
🔓 해결 방법
df.loc[df['new_price'].isin(list)]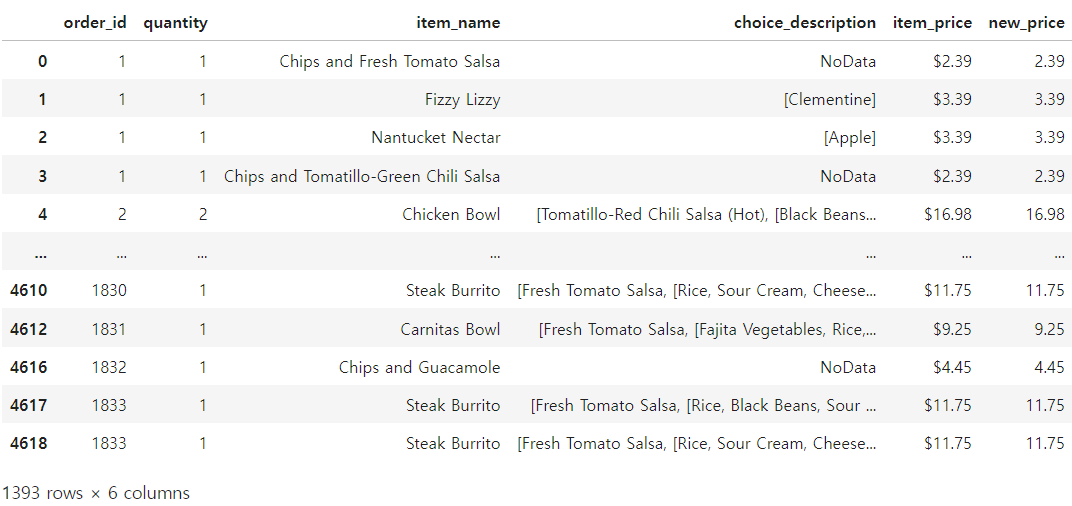
.isin( )을 이용하여 list에 포함된 내용이 해당 컬럼에 들어가 있는지 확인하는 코드를 통해 출력하였다.
isin( )에 대한 내용도 따로 찾아서 공부해야겠다..
'📒 Today I Learn > 🐼 Pandas' 카테고리의 다른 글
| [Pandas] Apply & Map (0) | 2024.07.17 |
|---|---|
| [Pandas] Pandas? (0) | 2024.07.17 |
| [Pandas] Filtering & Sorting (1) (0) | 2024.07.12 |
| [Pandas] Getting & Knowing Data (2) (0) | 2024.07.11 |
| [Pandas] Getting & Knowing Data (1) (0) | 2024.07.10 |