
2024.07.16

✳️ .groupby( )
데이터를 그룹화하여 연산을 수행하는 method
- by : 그룹화할 내용이다. 함수, 축, 리스트 등등이 올 수 있다.
- axis : 그룹화를 적용할 축이다.
- level : 멀티 인덱스의 경우 레벨을 지정할 수 있다.
- as_index : 그룹화할 내용을 인덱스로 할지 여부입니다. False이면 기존 인덱스가 유지된다.
- sort : 그룹키를 정렬할지 여부이다.
- group_keys : apply메서드 사용시 결과에따라 그룹화 대상인 열이 인덱스와 중복(group key)이 될 수 있다. 이 때, group_keys=False로 인덱스를 기본값으로 지정할 수 있다.
- squeeze : 결과가 1행 or 1열짜리 데이터일 경우 Series로, 1행&1열 짜리 데이터일 경우 스칼라로 출력한다.
- observed : Categorical로 그룹화 할 경우 Categorical 그룹퍼에 의해 관찰된 값만 표시할 지 여부이다.
- dropna : 결측값을 계산에서 제외할지 여부이다.
오늘 빅분기 기출 100문제를 풀면서 배우게 된 부분만 정리해서 글을 써본다.
추가 내용의 경우는 좀 더 공부를 해보고 내용을 추가해볼 예정!
먼저 이러한 데이터가 있다고 가정하자.
import pandas as pd
import numpy as np
idx=['A','A','B','B','B','C','C','C','D','D','D','D','E','E','E']
col=['col1','col2','col3']
data = np.random.randint(0,9,(15,3))
df = pd.DataFrame(data=data, index=idx, columns=col).reset_index()
print(df)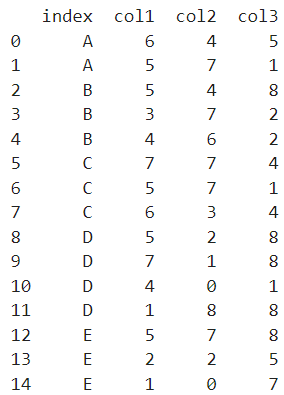
먼저 index 컬럼에 대해서 groupby 수행을 해보았다.
print(df.groupby('index'))
# <pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001AE58371160>이제 이 데이터는 'index'로 그룹화 되어 있다!
🔹 그룹화 된 상태로 연산
print(df.groupby('index').mean())
🔹 추가 method 적용
단순 연산 method가 아닌 여러 method를 적용 할 수 있다.
print(df.groupby('index').agg(['sum','mean']))
🔹 as_index 인수 사용
groupby를 하면 지정된 특정열에 대해 해당 열이 인덱스가 된다. 이때 as_index=False를 입력해주면서 기존의 인덱스 유지가 가능해진다.
def top (df,n=2,col='col1'):
return df.sort_values(by=col)[-n:]
print(df.groupby(['index'],as_index=False).sum())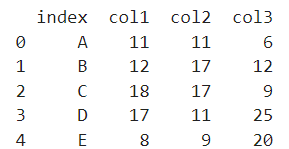
🔹 dropna 인수 사용
dropna를 통해 결측값(NaN)이 포함된 경우, 그룹화에서 제외할지 여부를 정할 수 있다.
현재 데이터 중에 6번째 행을 결측값으로 변경하고 실험해보자.
df.loc[6,'index'] = np.NaN
print(df)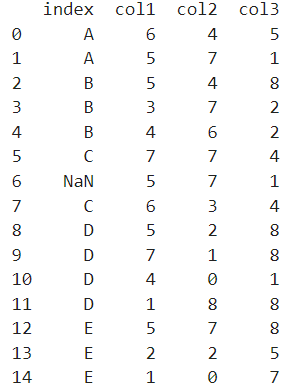
print(df.groupby('index').sum())
일반적으로 결측값은 계산에서 제외되어 인덱스에 표시가 되지 않는다.
print(df.groupby('index',dropna=False).sum())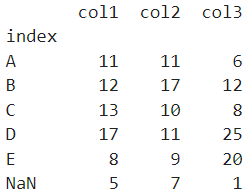
dropna=False인 경우 인덱스에 NaN이 포함되어 계산된 것을 알 수 있었다.
<참고 자료>
02-11. 그룹화 계산 (groupby)
####DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squee…
wikidocs.net
'📒 Today I Learn > 🐍 Python' 카테고리의 다른 글
| [Pandas] stack( ) & unstack( ) (0) | 2024.07.17 |
|---|---|
| [Pandas] Grouping (0) | 2024.07.16 |
| [Pandas] count & size (0) | 2024.07.16 |
| [Python] 파이썬에서 like 검색 - .str.startswith() & .str.contains() (0) | 2024.07.15 |
| [Pandas] 데이터프레임 값 바꾸기 (변경, replace) (0) | 2024.07.15 |