
2024.07.16

🔒 44번) 데이터를 로드하고 상위 5개 컬럼을 출력하라
DataUrl = 'https://raw.githubusercontent.com/Datamanim/pandas/main/AB_NYC_2019.csv'
🔓 해결방법
import pandas as pd
DataUrl = 'https://raw.githubusercontent.com/Datamanim/pandas/main/AB_NYC_2019.csv'
df = pd.read_csv(DataUrl)
df.head(5)
🔒 45번) 데이터의 각 host_name의 빈도수를 구하고 host_name 컬럼 기준으로 정렬하여 상위 5개를 출력하라
🔓 해결방법
# 해당 컬럼에 대한 데이터프레임을 출력해봤다
df[['host_name']]
host_name으로 여러 명의 이름과 인덱스를 출력해볼 수 있었다.
df['host_name'].value_counts()
.value_counts() 를 이용하여 개수를 세줬다. 이제 정렬을 하고 5개를 잘라내면 된다.
df['host_name'].value_counts().sort_index().head(5)
.sort_index() 를 이용하여 인덱스 기준으로 정렬해줬다. 기본으로 오름차순을 해준다.
다른 방법!
df.groupby('host_name').size().head(5)
.groupby() 로 해당 컬럼을 그룹화 시키고,
.size() 을 이용하여 개수를 카운팅해줬다.
df.groupby('host_name').count().head(5)
.count( )를 해주니 데이터 프레임 형태로 출력이 되었다.
▼ size, count 관련 내용
https://se0ehe.tistory.com/111
[Pandas] count & size
2024.07.16 데이터의 개수를 계산해주는 method인 두 함수의 차이와 기능에 대해서 정리하였다. ✳️ .count( )🔹 각 컬럼에 몇 개의 데이터가 있는지 계산해주며, NaN 값은 포함하지 않는다. 🔹
se0ehe.tistory.com
🔒 46번) 데이터의 각 host_name의 빈도수를 구하고 빈도수 기준 내림차순 정렬한 데이터 프레임을 만들어라. 빈도수 컬럼은 counts로 명명하라
🔓 해결방법
df.groupby('host_name').size().to_frame().rename(columns={0:'counts'}).sort_values('counts',ascending=False)
🔒 47번) neighbourhood_group의 값에 따른 neighbourhood컬럼 값의 갯수를 구하여라
🔓 해결방법
# 해당 컬럼에 대해 고유값 확인
df['neighbourhood_group'].unique()
일단 먼저 고유한 값을 확인해봤다. 해당 컬럼을 기준으로 그룹화시키면 5개의 그룹이 생길 수 있음을 알 수 있었다.
df.groupby(['neighbourhood_group', 'neighbourhood']).size()
neighbourhood_group에 따른 neighbourhood의 개수를 구했다. 맨 뒤의 값들이 size 컬럼으로 데이터 개수를 나타낸 것이다.
df.groupby(['neighbourhood_group', 'neighbourhood'], as_index=False).size()
그리고 as_index=False를 통해 그룹 연산의 결과를 인덱스가 아닌 정규 열로 반환시켰다.
▼ groupby와 as_index 관련 내용
https://se0ehe.tistory.com/112
[Pandas] groupby( )
2024.07.16 ✳️ .groupby( )데이터를 그룹화하여 연산을 수행하는 methodby : 그룹화할 내용이다. 함수, 축, 리스트 등등이 올 수 있다.axis : 그룹화를 적용할 축이다.level : 멀티 인덱스의 경우 레벨
se0ehe.tistory.com
🔒 48번) neighbourhood_group의 값에 따른 neighbourhood컬럼 값 중 neighbourhood_group그룹의 최댓값들을 출력하라
🔓 해결방법
a = df.groupby(['neighbourhood_group', 'neighbourhood'], as_index=False).size()
a.groupby(['neighbourhood_group'], as_index=False).max()식이 길어서 변수를 지정하였다.
a에는 neighbourhood_group과 neighbourhood을 groupby하여 이에 대한 데이터의 개수를 .size()를 통해 구하였고
neighbourhood_group의 데이터 개수 중 최댓값에 해당한 것을 .max() 를 이용해 출력한 것이다.
a.sort_values(['neighbourhood_group', 'size'], ascending=[True, False]).drop_duplicates('neighbourhood_group', keep='first')또 다른 식으로는 neighbourhood_group을 기준으로 groupby를 다시 하는 것이 아니라
neighbourhood_group와 size를 기준으로 데이터 값을 내림차순으로 정렬한 뒤 neighbourhood_group의 중복된 값을 제거하는 것으로 코드를 짤 수도 있다.

🔒 49번) neighbourhood_group 값에 따른 price값의 평균, 분산, 최대, 최소 값을 구하여라
🔓 해결방법
df[['neighbourhood_group','price']].groupby('neighbourhood_group').agg(['mean','var','max','min'])
.agg( ) 를 이용하여 다양한 연산을 한꺼번에 할 수 있다.
🔒 50번) neighbourhood_group 값에 따른 reviews_per_month 평균, 분산, 최대, 최소 값을 구하여라
🔓 해결방법
df[['neighbourhood_group','reviews_per_month']].groupby('neighbourhood_group').agg(['mean', 'var', 'max', 'min'])
위 문제와 동일하게 풀었다.
🔒 51번) neighbourhood 값과 neighbourhood_group 값에 따른 price 의 평균을 구하라
🔓 해결방법
df.groupby(['neighbourhood', 'neighbourhood_group'], as_index = False).price.mean()df.groupby(['neighbourhood', 'neighbourhood_group'], as_index = False)['price'].mean()
두 코드 동일한 방법이다. 두 컬럼에 대해 groupby된 가격의 평균을 구하기 위해 .mean() 을 이용해서 평균값을 구한 것이다.
🔒 52번) eighbourhood 값과 neighbourhood_group 값에 따른 price 의 평균을 계층적 indexing 없이 구하라
🔓 해결방법
계층적 인덱싱이 뭔지 몰라서 찾아보니,,,

이런 식으로 인덱스가 여러개에 값이 도출된 경우인 것 같았다. 이 부분에 대해서는 추후에 학습하며 익혀야겠다.
df.groupby(['neighbourhood', 'neighbourhood_group'])['price'].mean().unstack()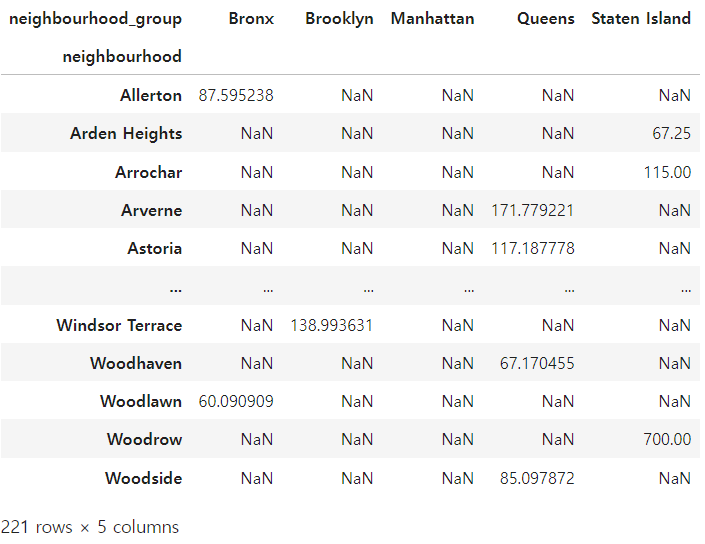
아모튼 원하는 형태는 피봇테이블같은 형태였던 것인데 neighbourhood_group과 neighbourhood를 인덱스와 컬럼으로 교체 하여 이에 대한 값을 표시해야 했다.
이를 위한 method로 .unstack() 를 이용하였다.
▼ unstack에 관한 내용
https://se0ehe.tistory.com/115
[Pandas] stack( ) & unstack( )
✳️ unstack : index to column파라미터 level: unstack을 수행할 인덱스 레벨을 지정여러 개의 레벨을 지정할 수 있으며, 이 경우 데이터프레임이 멀티인덱스를 가지게 됨기본값은 -1로, 마지막 인덱스
se0ehe.tistory.com
🔒 53번) neighbourhood 값과 neighbourhood_group 값에 따른 price 의 평균을 계층적 indexing 없이 구하고 nan 값은 -999값으로 채워라
🔓 해결방법
df.groupby(['neighbourhood', 'neighbourhood_group'])['price'].mean().unstack().fillna(-999)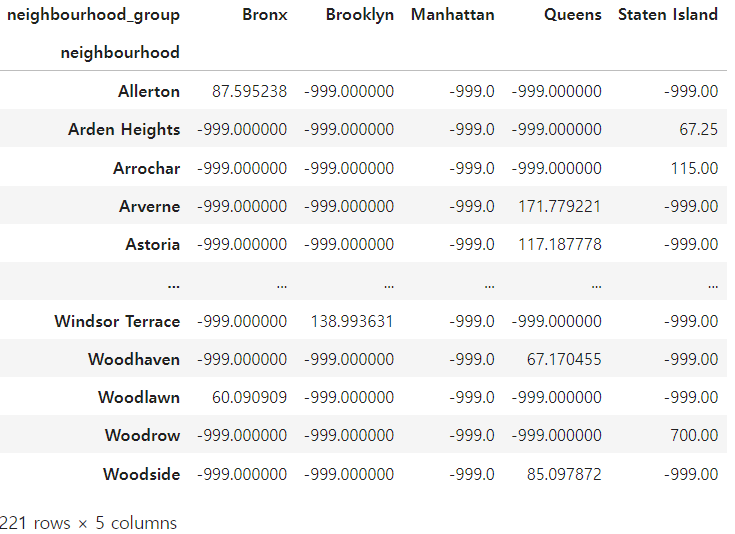
결측치를 -999로 바꾸기 위해서 .fillna( ) 를 이용하였다.
🔒 54번) 데이터중 neighbourhood_group 값이 Queens값을 가지는 데이터들 중 neighbourhood 그룹별로 price값의 평균, 분산, 최대, 최소값을 구하라
🔓 해결방법
a = df[df['neighbourhood_group'] == 'Queens']
b = a.groupby('neighbourhood').price.agg(['mean', 'var', 'max', 'min'])
print(b)
평균, 분산, 최대, 최소를 구하기 위해 describe( )를 써줘도 되지만,
딱 네가지 종류의 결과를 보이기 위해 .agg( ) 를 이용하여 여러 연산을 동시에 수행하여 결과를 도출해냈다.
▼ agg에 관한 내용
https://se0ehe.tistory.com/117
[Pandas] .agg( )
✳️ agg( )aggregate라는 축약어로 여러 함수들을 모아서 연속적으로 적용시킬 수 있는 method df.agg(func=None, axis=0, args, kwargs)func : 함수axis :{0 : index(row) / 1 : columns} 축으로 0은 행, 1은 열 arg : 함수
se0ehe.tistory.com
🔒 55번) 데이터중 neighbourhood_group 값에 따른 room_type 컬럼의 숫자를 구하고 neighbourhood_group 값을 기준으로 각 값의 비율을 구하여라
비율 = (각 Size 값 / 같은 그룹의 size 값 합)

🔓 해결방법
a = df.groupby(['neighbourhood_group','room_type'], as_index = False).size()
print(a)
먼저 그룹화를 통해 이웃 그룹 컬럼과 룸타입 컬럼에 해당되는 데이터 개수를 size를 통해 카운팅 해준다.
a = df.groupby(['neighbourhood_group','room_type']).size().unstack()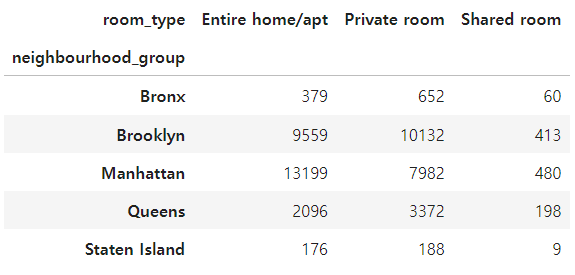
이웃 그룹 컬럼과 룸타입 컬럼을 다음과 같이 각각 인덱스와 컬럼의 형태로 만들어 피봇테이블처럼 구현했다.
# 각 행에 따라 값을 더하기
a.sum(axis=1)
sum() 을 이용하여 더하기를 해줄 것인데 이때 행에 대한 값들을 더해야 해서 axis=1로 지정해준다.
# numpy 함수인 reshape을 이용하여 차원을 하나 더 늘려줌
a.sum(axis=1).values.reshape(-1, 1)
a.sum(axis=1).values
# 연산을 하기에 차원이 맞지 않다
a.sum(axis=1).values.shape
# (5,)a.sum(axis=1).values.reshape(-1, 1).shape
# (5, 1) 차원을 맞춰주기- 최종 코드
a = df.groupby(['neighbourhood_group','room_type'], as_index = False).size()
a.loc[:,:] = (a.values / a.sum(axis=1).values.reshape(-1, 1))
a.loc[:,:] 혹은 a
a.loc[:,:]나 a를 주피터 환경에서 찍어보면 다음과 같이 비율이 출력되어진다.
'📒 Today I Learn > 🐍 Python' 카테고리의 다른 글
| [Pandas] .isin( ) (0) | 2024.07.17 |
|---|---|
| [Pandas] stack( ) & unstack( ) (0) | 2024.07.17 |
| [Pandas] groupby( ) (0) | 2024.07.16 |
| [Pandas] count & size (0) | 2024.07.16 |
| [Python] 파이썬에서 like 검색 - .str.startswith() & .str.contains() (0) | 2024.07.15 |