

✳️ 데이터 불러오기와 저장하기
- 불러오기 : .read_*
파일을 불러오는 method로, ' * ' 에는 파일 형식을 넣어주면 된다. - 저장하기 : to_*
저장을 하기 위한 method로, 마찬가지로 ' * ' 에 파일 형식을 입력하면 된다.

코드 예시)
# panas를 이용할 것이기 때문에 pandas를 불러와준다.
import pandas as pd
# seaborn 라이브러리에서 내장 데이터를 불러와 실습할 것이라서 불러와줌.
import seaborn as sns먼저 필요한 라이브러리를 import 해준다.
data = sns.load_dataset('tips')
data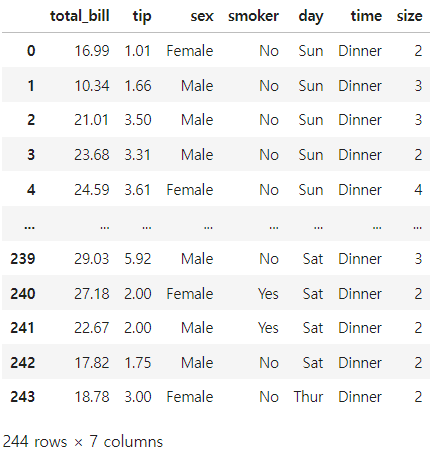
seaborn에 내장 되어 있는 'tips' 데이터셋을 data 변수에 할당해준다.
⭐ 데이터 저장하기
먼저 이 'tips' 데이터를 나의 개인 폴더에 저장을 해주는 과정을 실습하기!
csv 파일 형식과 excel 파일 형식으로 저장
data.to_csv('tips_data.csv')이렇게 코드를 입력하면 저장 위치가 현재 작업하고 있는 파일에 저장된다고 한다.
# csv로 저장하기
data.to_csv('pandas_practice/tips_data.csv', index=False)
이렇게 파일명 앞에 폴더명과 ' / ' 를 넣어주면 해당 폴더에 저장이 된다.
# excel로 저장하기
df.to_excel("pandas_practice/tips_data.xlsx", index=False)
엑셀로도 마찬가지로 동일하게 저장하지만 확장자명과 파일 형식을 잘 입력하자!
주피터노트북 자체에서는 엑셀이 안 열리는지 저걸 누르면 오류가 났었다..
하지만 파일은 제대로 저장된 것은 맞았다! 엑셀에서 열면 열리는 걸 확인하였다!
그런데 index=False.. 저게 뭐지? 싶을 수 있는데 이것은 파일 불러오기에서 예시와 함께 정리하였다.
⭐ 파일 불러오기
저장을 마쳤으니 이제 정말 파일을 불러와 보자!
df = pd.read_csv("tips_data.csv")
df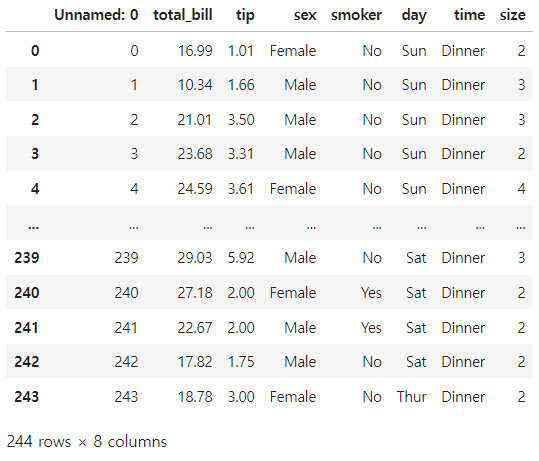
df라는 변수에 읽어온 파일을 할당하고 df를 출력해보면 데이터프레임이 출력된다.
그런데 여기서 ! Unnamed: 0 컬럼 ! 이라는 이상한 열이 있는 걸 확인할 수 있다.
이것은 파일을 저장할 때 인덱스를 따로 지정하지 않았기 때문에 인덱스가 컬럼으로 들어가버린 사태가 발생한 것이다.
이걸 해결하는 방법!
1. 저장할 때 인덱스를 빼주기
data.to_csv("tips_data.csv", index=False)파일을 저장할 때 index는 기본적으로 새로 형성되게 되어 있다.
그래서 디폴트로 index는 True인 상태로 되어 있어서 아무것도 입력하지 않아도 True인 형태로 만들어지게 된다.
여기서 False로 바꿔줘야 따로 인덱스를 지정하지 않고 저장을 해준다.
df = pd.read_csv("tips_data.csv")
df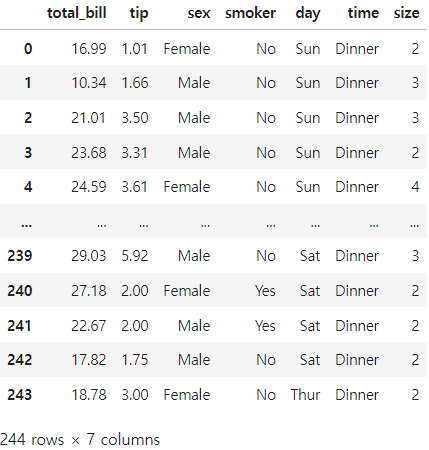
index=False로 하고 저장된 파일을 다시 불러와보면 Unnamed: 0 컬럼이 사라졌다.
2. 불러올 때 인덱스 빼주기
df = pd.read_csv("tips_data.csv", index_col=0)만일 내가 만든 데이터셋이 아니고 남이 만든 데이터셋에서 불러와보니 인덱스가 컬럼이 된 상태라면 불러올 때 빼주는 방법도 있다. 그건 따로 인덱스가 될 열을 지정해주는 방식이다.
index_col=0은 0번째 열을 인덱스로 뽑아 달라고 명령해준 것이다.
그래서 다시 데이터를 출력 시켜 보면 아까처럼 Unnamed: 0 컬럼은 사라진 걸 확인할 수 있다.
➕ 추가 내용
주피터 노트북에서 터미널 창을 열고 따로 작업해야 하는 경우가 생긴다면 !를 써서 작업을 진행하면 편하다.
! pip install openpyxl
엑셀 깔아 달라는 것인데 이미 어디어디여기에 잘 깔려 있다고 알려주는 것 같다.
▼ 이 내용의 참고
https://blog.naver.com/kiddwannabe/221581996306
Jupyter notebook 에서 pip install 직접 하기
파이썬에 기본 설치되어있거나, 아나콘다에 포함되어 설치된 라이브러리가 아닐 경우에는 직접 라이브러리...
blog.naver.com
'📒 Today I Learn > 🐼 Pandas' 카테고리의 다른 글
| [Pandas] 데이터 확인 (0) | 2024.07.19 |
|---|---|
| [Pandas] 인덱스 & 컬럼 (0) | 2024.07.18 |
| [Pandas] Apply & Map (0) | 2024.07.17 |
| [Pandas] Pandas? (0) | 2024.07.17 |
| [Pandas] Filtering & Sorting (2) (0) | 2024.07.15 |