

💟 데이터 전처리 및 EDA
☑️ 데이터 전처리
- 우리 조가 선택한 데이터의 가장 까다로운 점은 대부분 범주형 데이터였다는 점
- 결측치가 존재하는 컬럼이 5개였던 점
이러한 문제점이 존재해서 데이터를 전처리할 때 다음과 같이 전처리를 해줬다.
1️⃣ 나이 컬럼의 재범주화와 다중응답 처리
- 나이 재범주화
나의 범주를 살펴보면 다소.. 기존 데이터가 애매하게 범주를 나눠진 상태였다.

우리 조는 이 나이 범주를 20세 미만, 20-35세, 35세 이상으로 기준을 다시 나눠서 다음과 같은 코드로 데이터를 재범주화 시켰다.
df['Age'] = df['Age'].replace({'6-12' : 'under_20', '12-20' : 'under_20', '35-60' : 'over_35', '60+' : 'over_35'})df['Age'].value_counts()
크게 세가지 나이대별로 범주화를 하니 애매했던 6-12세 데이터와 60세 이상 데이터를 묶을 수 있었다.
- 다중 응답 처리(one-hot-encoding 이용)
다중 응답 처리는 컬럼중에 value를 카운트 했을 때 다음과 같은 결과를 볼 수 있었다.

우리도 설문 조사를 하면 다중 선택이 가능한 설문조사를 가끔 마주하는데 그러한 항목이었던 것으로 추정되었고, 우리는 이러한 다중 선택 컬럼들이 총 4개의 컬럼이 존재하는 것을 알게 되었다.
좀 더 깔끔하고 추후에 데이터를 활용하기 위해 응답의 항목을 분리해서 개별적으로 변수를 생성해줬다.
(컬럼을 따로 만들어줌!)
여기서 나는 코딩 능력치가 매우 낮기 때문에 하드코딩을 했었따....ㅎ
함수를 정해서 분리한 항목이 값에 들어 있다면 1을 추가해주는 방식을 이용해서


이렇게 각 컬럼을 생성해, apply로 함수를 일괄 적용 시켜주었다. 데이터를 확인해보면,

마지막 컬럼(' pod_variety_satisfaction ')을 뒤로 각각 분리했던 항목들이 컬럼으로 추가되고, 의도했던 대로 카운팅이 잘 된 것을 확인할 수 있었다.
그래서 나머지 다중응답 컬럼들도 이런식으로 하드코딩을 해줬는데, 팀장님의 센스있는 코드를 보고 한 수 배워갔다.
# 스마트폰 항목 분리
spotify_df['device_smartphone'] = spotify_df.spotify_listening_device.map(lambda x : 1 if 'Smartphone' in x.split(', ') else 0)
# 컴퓨터 또는 노트북 항목 분리
spotify_df['device_Computer_or_laptop'] = spotify_df.spotify_listening_device.map(lambda x : 1 if 'Computer or laptop' in x.split(', ') else 0)
# 스마트스피커 또는 음성보조 항목 분리
spotify_df['device_Smart_speakers_or_voice_assistants'] = spotify_df.spotify_listening_device.map(lambda x : 1 if 'Smart speakers or voice assistants' in x.split(', ') else 0)
# 착용장비 항목 분리
spotify_df['device_Wearable_devices'] = spotify_df.spotify_listening_device.map(lambda x : 1 if 'Wearable devices' in x.split(', ') else 0)lambda를 사용하셨고 split을 이용해서 , 기준으로 항목이 포함되면 1을 아니면 0을 넣어달라고 하는 걸 map을 이용해 묶어서 적용하셨다.
또 다른 팀원 분의 전처리도 좋았었다. 이 분은 데이터프레임을 아예 새로 생성을 해주신 경우였는데,
만일 기존 데이터에 추가되는 것이 싫고 따로 이용할 데이터로 여긴다면 이러한 방법을 이용하는 것도 좋은 방법이라고 생각했다.
devices = ['Smartphone', 'Computer or laptop', 'Smart speakers or voice assistants', 'Wearable devices']
for device in devices:
df[device] = df['spotify_listening_device'].apply(lambda x: 1 if device in x else 0)
df[devices]재분류를 할 때 먼저 각각의 항목 리스트를 변수에 넣어주고
devices 리스트를 for문을 돌리면서 기존의 데이터프레임 중, devices리스트에 포함되어 있는 것이 있으면 1, 없으면 0을 넣어주고 새로운 데이터프레임을 생성하는 코드였다.

2️⃣ 결측치 확인 및 활용
보통은 결측치를 제거하거나 대체하는 방식을 이용해서 처리를 하는데 우리는 결측치가 있는 컬럼을 확인하고 그 값의 개수를 보았다. 팀원분께서, 이 결측치가 있는 것이 특히 팟캐스트와 연관된 취향조사 질문에 많이 있다라는 것을 보시고, 팟캐스트 서비스에 대한 고객의 관심도가 낮음을 분석해볼 수 있지 않을까라고 제안해주셨다.
그래서 우리는 따로 결측치를 제거하거나 대체하지 않고 이것을 오히려 활용해서 팟캐스트 사업의 방향과 개선점을 찾고자 하였다.

import missingno as ms
ms.matrix(df = spotify_df)
plt.show()팀장님께서 이 결측치 부분을 시각화하는 법을 찾으셨는데 missingno라는 라이브러리를 이용할 수 있었다.

아.. 정말 내가 너무 좋아하는 시각화 스타일...
아가로스 젤 사진같고.. 넘 좋다..ㅋㅅㅋ 비어있는 부분이 결측치인데, 한 눈에 보기 너무 좋았다!!!
진짜.. 시각화의 세계는 넓고 공부해두면 유용하게 쓰일 것 같다는 생각이 들었다.
☑️ 데이터 탐색

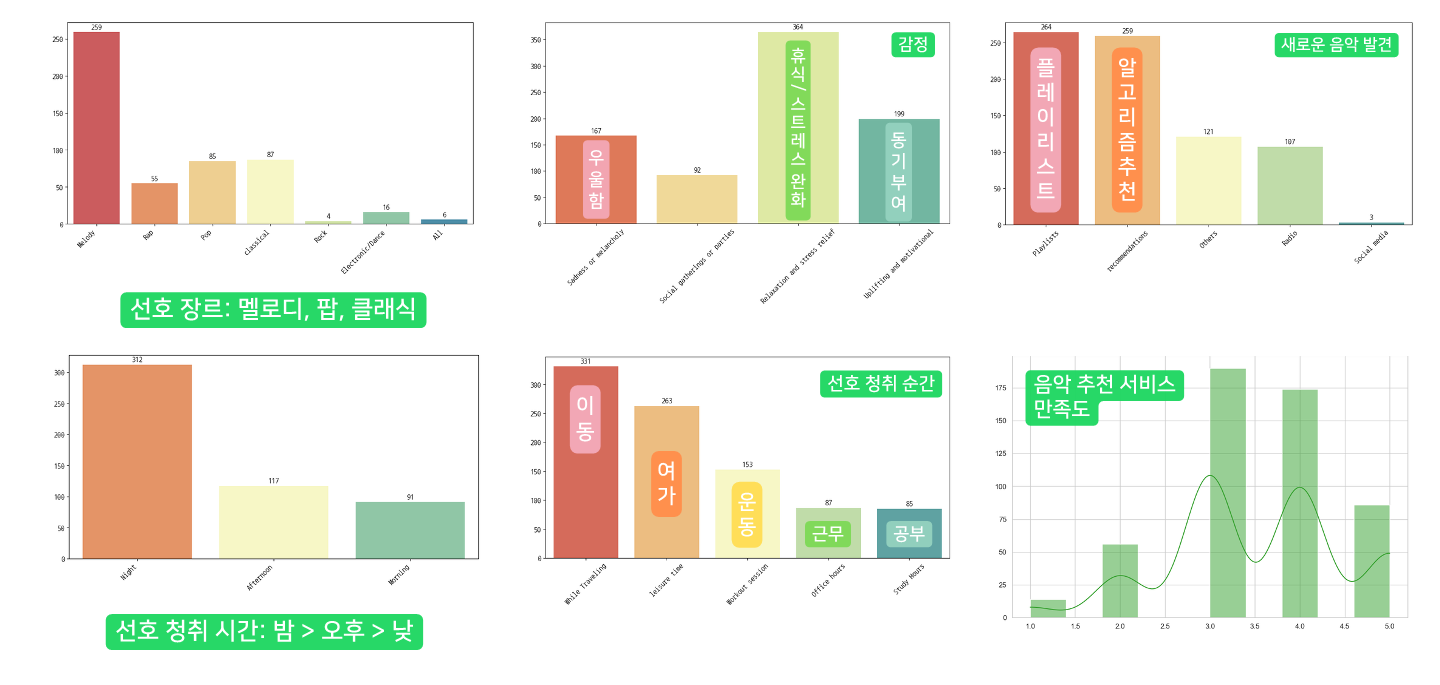

각각의 데이터들의 전반적인 탐색을 위해 팀원분께서 시각화 자료로 만들어 주셨다.
대단한 능력자분들이.. 우리 팀에 계셔서.. 나는 정말 많이 도움을 받았다ㅠㅠㅠㅠㅠ
'📊 Data Analysis > 📗 Basic Project' 카테고리의 다른 글
| [기초 프로젝트] 음악 플랫폼 유저 행동 데이터 분석 (4) (0) | 2024.08.05 |
|---|---|
| [기초 프로젝트] 음악 플랫폼 유저 행동 데이터 분석 (3) (0) | 2024.08.01 |
| [기초 프로젝트] 음악 플랫폼 유저 행동 데이터 분석 (1) (0) | 2024.07.24 |